- Code: Select all Expand view
FW_SetUnicode( .T. )
at the very beginning, particulary before any Window or Dialog is created for the first time. After the first window/dialog is created, this setting can not be changed.
Rest of the discussion in this post apply to Unicode applications only and for ANSI (non-Unicode) applications, the behavior continues to be as has always been.
Non-Character Gets are always ANSI:
Even in a Unicode application, Unicode character input is enabled only for character variables. Gets of all other variables (types like DLNT) behave identical to pure ANSI Gets.
By default, any Get of a character variable in a Unicode application accepts Unicode characters. Unicode character Gets (hereafter referred to as Unicode Gets) do not respect any picture clause except "@!".
ANSI Gets in Unicode Application:
However, it is possible to create a pure ANSI Get even in a Unicode application by including the clause "CHRGROUP CHR_ANSI". Such Gets do not accept Unicode characters and behave identical to Gets in a pure ANSI application. These Gets can have picture clauses like any ANSI Get.
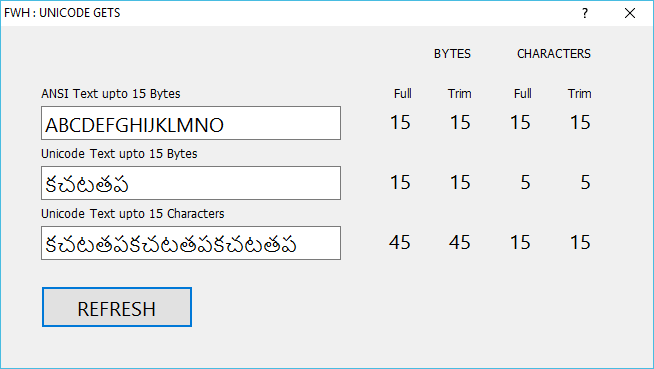
Maximum possible length of input in Unicode Get:
By default Get restricts the length of the input to the same number of bytes as the length of the variable in bytes. If cVar is Space(15), GET ... cVar restricts the input to 15 bytes. Because on average each Unicode character occupies 3 bytes, we can not input a Unicode text exceeding 5 Unicode characters or 15 bytes. In case the trimmed length of input text is less than 15 bytes, the value is right padded to 15 bytes.
Note:
Len( cVar ) --> Length in Bytes
HB_UTF8LEN( cVar ) --> Length in Characters.
In the case of English, Len( cVar ) is always the same as HB_UTF8LEN( cVar )
This default behavior suits XBase applications. Character field with length 15 can strore maximum of 15 byte of text whether ANSI or Unicode. So in effect maximum Unicode text that can be stored is approximately 5 characters.
The case of SQL servers is different. For example, VarChar(15) in MySql with utf8 charset or NVARCHAR(15) in MsSql/Oracle,etc accommodate 15 characters even if the length in bytes exceeds 15 bytes. To meet the requirements of these databases we need a different behavior of Get object.
cVar := Space(15)
@ r,c GET cVar ........ CHRGROUP CHR_WIDE
meets this requirement.
In this case, the user input is restricted to 15 characters not bytes. The returned value is padded to 15 characters, i.e., HB_UTF8LEN( cVar ) will be 15 though Len( cVar ) may be >= 15 depending on the type of characters input.
The following sample may be tried to test this functionality.
- Code: Select all Expand view
#include "fivewin.ch"
function TestUnicodeGets()
local aText[ 3 ]
local aGets[ 3 ]
local oDlg, oSegoe, oSmall
FW_SetUnicode( .T. )
AFill( aText, Space( 15 ) )
DEFINE FONT oSmall NAME "TAHOMA" SIZE 0,-12
DEFINE FONT oSegoe NAME "Segoe UI" SIZE 0,-20
DEFINE DIALOG oDlg SIZE 650,340 PIXEL TRUEPIXEL FONT oSegoe ;
TITLE "FWH : UNICODE GETS"
@ 20, 360 SAY "BYTES" SIZE 110,34 PIXEL OF oDlg FONT oSmall RIGHT
@ 20, 480 SAY "CHARACTERS" SIZE 110,34 PIXEL OF oDlg FONT oSmall RIGHT
@ 60, 40 SAY "ANSI Text upto 15 Bytes" SIZE 300,20 PIXEL OF oDlg FONT oSmall
@ 60, 360 SAY "Full" SIZE 50,20 PIXEL OF oDlg FONT oSmall RIGHT
@ 60, 420 SAY "Trim" SIZE 50,20 PIXEL OF oDlg FONT oSmall RIGHT
@ 60, 480 SAY "Full" SIZE 50,20 PIXEL OF oDlg FONT oSmall RIGHT
@ 60, 540 SAY "Trim" SIZE 50,20 PIXEL OF oDlg FONT oSmall RIGHT
@ 80, 40 GET aGets[ 1 ] VAR aText[ 1 ] SIZE 300,34 PIXEL OF oDlg CHRGROUP CHR_ANSI VALID ( oDlg:Update(), .t. )
@ 80, 360 SAY Len( aText[ 1 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 80, 420 SAY Len( Trim( aText[ 1 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 80, 480 SAY HB_UTF8LEN( aText[ 1 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 80, 540 SAY HB_UTF8LEN( Trim( aText[ 1 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 120, 40 SAY "Unicode Text upto 15 Bytes" SIZE 300,20 PIXEL OF oDlg FONT oSmall
@ 140, 40 GET aGets[ 2 ] VAR aText[ 2 ] SIZE 300,34 PIXEL OF oDlg CHRGROUP CHR_ANY VALID ( oDlg:Update(), .t. )
@ 140, 360 SAY Len( aText[ 2 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 140, 420 SAY Len( Trim( aText[ 2 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 140, 480 SAY HB_UTF8LEN( aText[ 2 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 140, 540 SAY HB_UTF8LEN( Trim( aText[ 2 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 180, 40 SAY "Unicode Text upto 15 Characters" SIZE 300,20 PIXEL OF oDlg FONT oSmall
@ 200, 40 GET aGets[ 3 ] VAR aText[ 3 ] SIZE 300,34 PIXEL OF oDlg CHRGROUP CHR_WIDE VALID ( oDlg:Update(), .t. )
@ 200, 360 SAY Len( aText[ 3 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 200, 420 SAY Len( Trim( aText[ 3 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 200, 480 SAY HB_UTF8LEN( aText[ 3 ] ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 200, 540 SAY HB_UTF8LEN( Trim( aText[ 3 ] ) ) PICTURE "99" SIZE 50,34 PIXEL OF oDlg RIGHT UPDATE
@ 260, 040 BUTTON "REFRESH" SIZE 150,40 PIXEL OF oDlg ACTION oDlg:Update()
ACTIVATE DIALOG oDlg CENTERED
RELEASE FONT oSegoe, oSmall
return nil
When text is entered to maximum allowed length:
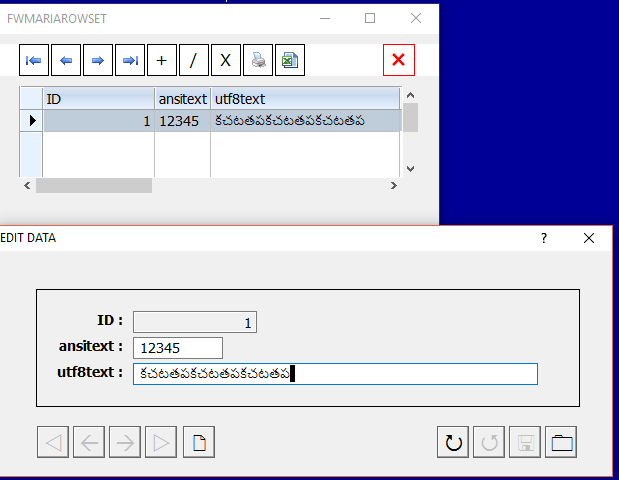
FW MARIADB RowSet:
Now let us see how does FWH implementation of MySql/MariaDB simplifies handling of ANSI and Unicode fields of tables.
First we need to establish Unicode connection to Server. In a Unicode application ( i.e., when FW_SetUnicode( .T. ) is called first), connection to MySql server is established as a Unicode connection.
When a table is opened, the RowSet object recognises the character set of each field of the table (or sql). XBrowse and DataRow objects are tightly integrated with FW MySql objects. Both XBrowse and DataRow objects learn from the RowSet object, which fields are to be edited as ANSI and which fields are to edited as Unicode with CHR_WIDE type.
A table's character set defaults to database's character set and fields' character set defaults to table's character set. Because defaults may be deceptive at times, it is highly recommended to specify the character set of table and fields at the time of creation of the table.
Example:
- Code: Select all Expand view
#include "fivewin.ch"
function TestUnicodeRowSet
local cHost := "localhost"
local cUser := "root"
local cPassword := <secret>
local cDB := "fwh"
local oCn, oRs
FW_SetUnicode( .t. )
FWCONNECT oCn HOST cHost USER cUser PASSWORD cPassword DATABASE cDb
if oCn == nil
? "Connect Fail"
return nil
endif
if .not. oCn:TableExists( "ansiutf" )
oCn:CreateTable( "ansiutf", { { "ansitext", 'C', 5, 0, "latin1" }, ;
{ "utf8text", 'C', 15, 0, "utf8" } }, ;
.t., "utf8" )
endif
oRs := oCn:RowSet( "ansiutf" )
XBROWSER oRs FASTEDIT
oRs:Close()
oCn:Close()
return nil
The above CreateTable() method internally generates the following SQL to create the table:
- Code: Select all Expand view
- CREATE TABLE `ansiutf` (
`ID` INT AUTO_INCREMENT PRIMARY KEY,
`ansitext` VARCHAR( 5 ) CHARACTER SET latin1 COLLATE latin1_general_ci,
`utf8text` VARCHAR( 15 ) CHARACTER SET utf8 COLLATE utf8_unicode_ci
) CHARACTER SET utf8 COLLATE utf8_unicode_ci
As long as we use FW MariaDB, XBrowse and default DataRow dialogs everything is automated without any special effort of the programmer.
But we do not always like to use DataRow's default dialogs and want to design our own dialogs. In such cases we need to specify for each Get whether to use CHR_ANSI or CHR_WIDE. Even this is simple
example:
- Code: Select all Expand view
function MyDialog( oRec )
@ r,c GET oRec:fieldname SIZE ........ CHRGROUP oRec:FieldnChrGrp( "fieldname" )
...
There is no need for the programmer to keep note of the character sets of different fields.
Note: If TDataRow is used for editing, default is CHR_WIDE.
When using 3rd party libs, the programmer should carefully declare the clauses CHR_ANSI / CHR_WIDE.

