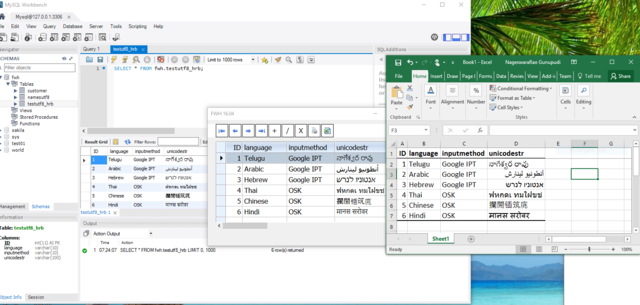
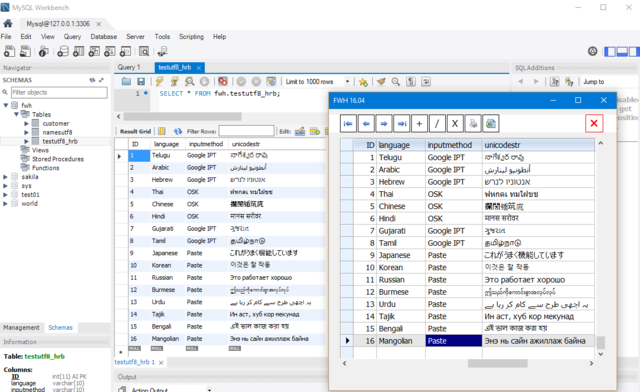
Mr Richard and Mr Dutch informed me that they prefer to use TDolphin or TMySql to ADO.
FWH does work with utf8 perfectly. An FWH+(x)Harbour program needs to communicate with MySql server through an intermediate interface. The interface can be:
1) ADO using TOleAuto() of Harbour --> Works Perfectly
2) ADO using TOleAuto() of xHarbour
3) TDolphin
4) TMySql
So the title of the topic should not be
UTF8 & MySql are 100% compatible with FWH?
The title should be something like
Which interface/3rd party libs are 100% compatible with utf8 and MySql.
Options (2) to (4) have limitations. It is possible to write and read unicode strings. The data is understood only by this software and no other software. MySql Workbench does not understand the data, which means that no other MySql connector also can not understand the data.
Also our software can not understand data written by other software.
Though TDolphin and TMySql are not fully compatible at present, it is easy to make them compatible fully.
This is the change required in tdolphin and tmysql source code:
TDolphin: Module "function.c"
Insert one line of code
- Code: Select all Expand view
mysql_set_character_set( mysql, "utf8" );
in the function HB_FUNC( MYSQLCONNECT )
- Code: Select all Expand view
HB_FUNC( MYSQLCONNECT ) // -> MYSQL*
{
<some code here>
mysql_real_connect( mysql, ....... );
mysql_set_character_set( mysql, "utf8" ); // New line inserted here
hb_MYSQL_ret( mysql );
TMySql: module "mysql.c"
In the function HB_FUNC( MYSQL_REAL_CONNECT )
Instead of this present code
- Code: Select all Expand view
if( mysql_real_connect( mysql, szHost, szUser, szPass, 0, port, NULL, flags ) )
hb_MYSQL_ret( mysql );
modify as
- Code: Select all Expand view
if( mysql_real_connect( mysql, szHost, szUser, szPass, 0, port, NULL, flags ) )
{
mysql_set_character_set( mysql, "utf8" ); // New line inserted here
hb_MYSQL_ret( mysql );
}
With this simple change, both Dolphin and TMySql are 100% compatible with utf8 and MySql. We can use either Harbour or xHarbour. Data written by our software is recognized by all outside software and MySql Workbench and our software can read and understand data written by other softwares.
I thank Mr Dutch and Mr Richard for testing and confirming the results with modified dolphin libraries.
ADO with xHarbour has limitations because its TOleAuto() works in ANSI mode only. So for xHarbour users wanting to work with multilingual unicode application using utf8 with MySql, the best choice is modifed dolphin or tmysql.
MySql server can handle not only utf8 different language character sets like big5 (chinese), tis620 (thai), utf8mb4, utf16 and many more. If we connect with 'utf8' it appears we still can read and write in amy othese encodings,
Again the best solution is FWH+ADO+Habour+MySql.
With this option, we can simultaneously read and write any language encoded by MySql in any character set.
Here is an example to show perfect working with 7 different encodings in the same table in many languages.
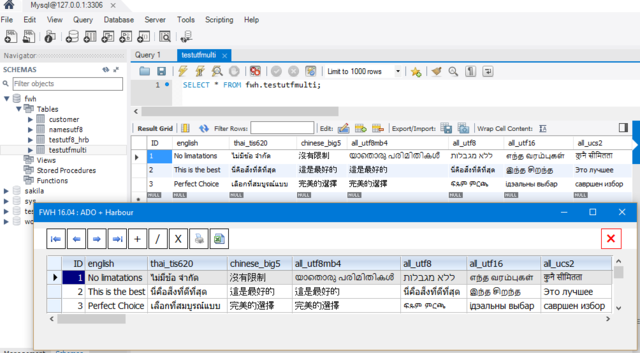
Program:
- Code: Select all Expand view
#include "fivewin.ch"
#include "adodef.ch"
#ifdef __XHARBOUR__
#error Does not run correctly with XHarbour
#endif
static oCn
//----------------------------------------------------------------------------//
function Main()
local oRs, cSql, aStruct, c
local cTable := "testutfmulti"
HB_SETCODEPAGE( "UTF8" )
FW_SetUnicode( .t. )
MsgRun( "Connecting to MySql Server", "MYSQL", { || ;
oCn := FW_OpenAdoConnection( "MYSQL,localhost,fwh,root,password", .t. ) ;
} )
if oCn == nil
? MsgStop( "Connect Fail" )
return nil
endif
if .not. FW_AdoTableExists( cTable, oCn ) .or. ;
MsgYesNo( "Recreate table " + cTable )
TRY
oCn:Execute( "DROP TABLE " + cTable )
CATCH
END
aStruct := { ;
{ "english", 'C', 30, 0 }, ;
{ "thai_tis620", "VARCHAR(100) CHARACTER SET tis620 COLLATE tis620_thai_ci" }, ;
{ "chinese_big5","VARCHAR(100) CHARACTER SET big5 COLLATE big5_chinese_ci" }, ;
{ "all_utf8mb4", "VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci" }, ;
{ "all_utf8", "VARCHAR(100) CHARACTER SET utf8 COLLATE utf8_unicode_ci" }, ;
{ "all_utf16", "VARCHAR(100) CHARACTER SET utf16 COLLATE utf16_general_ci" }, ;
{ "all_ucs2", "VARCHAR(100) CHARACTER SET ucs2 COLLATE ucs2_general_ci" } }
FWAdoCreateTable( cTable, aStruct, oCn )
endif
oRs := FW_OpenRecordSet( oCn, cTable )
XBROWSER oRs TITLE FWVERSION + " : ADO + Harbour" FASTEDIT SETUP ( ;
oBrw:lCanPaste := .t., ;
oBrw:AutoFit(), ; // use autofif() only with FWH16.04
oBrw:bRClicked := { |r,c,f,o| o:oRs:Requery(), o:GoTop(), o:Refresh() } )
oRs:Close()
oCn:Close()
return nil
//----------------------------------------------------------------------------//
Finally,
FWH on its part works perfectly with utf8. We need never question whether FWH is compabitle or not.
The question is what interface is compatible and with what limitations.
We demonstrated here that the option of ADO+Harbour is the best choice.
We also discussed how to make other alternatives work perfectly as long as the encoding is ANSI or UTF8.
Now it is for the programmer to choose the right interface depending on his requirements and what limitations he can live with.