Imaginad que tenemos un robot y queremos que el robot aprenda la forma más eficiente de salir de una casa.
Asi que situamos en robot en una habitación al azar y el robot intenta salir de la casa.
El robot aprende de los éxitos y de los fallos, y comienza a mejorar. En unos pocos intentos el robot sabe
la forma más eficiente de salir de la casa
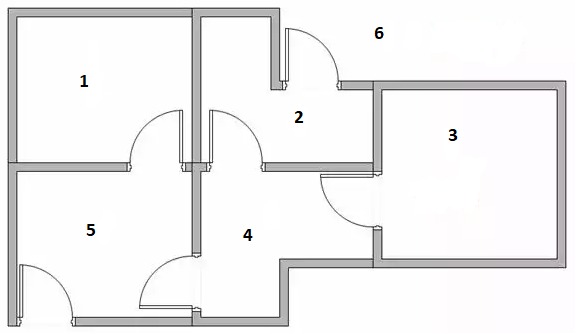
Si el robot comienza en la habitación 1 ó en la habitación 3, no hay nada que elegir. Desde la habitación 1 él solo puede ir a la habitación 5.
Desde la habitación 3 él solo puede ir a la habitación 4.
Si está en la habitación 2, entonces tiene dos opciones, salir de la casa (él no sabe que es la salida pero será recompensado)
ó puede ir a la habitación 4.
Una situación similar ocurre en la habitación 5. Puede salir de la casa (y ser recompensado) ó puede ir a la habitación 4 ó a la 1.
Cuando el robot está en la habitación 4 él tiene dos alternativas para salir: ir a través de la habitación 5 ó ir a través de la habitación 2.
Ambos caminos le sacarán de la casa con la misma cantidad de pasos.
Cuando el robot sale de de la casa, él consigue un refuerzo positivo (el dato nScore del objeto State se incrementa en 0.1).
Cuando falla, él obtiene un refuerzo negativo (el dato nScore del objeto State se decrementa en 0.1). Después de unos pocos
intentos el robot aprende la forma correcta.
qlearning.prg
- Code: Select all Expand view
- #include "FiveWin.ch"
static aStates
//----------------------------------------------------------------------------//
function Main()
local n
aStates = InitStates()
for n = 1 to 10
? "Number of steps to exit", SolveIt()
next
XBrowse( aStates )
return nil
//----------------------------------------------------------------------------//
function SolveIt()
local oState, nSteps := 0
oState = aStates[ hb_RandomInt( 1, Len( aStates ) - 1 ) ]
while ! oState == ATail( aStates )
XBrowse( oState:aOptions, "Options for room: " + AllTrim( Str( oState:nId ) ) )
oState = oState:NextState()
nSteps++
end
return nSteps
//----------------------------------------------------------------------------//
function InitStates()
local aStates := Array( 6 )
AEval( aStates, { | o, n | aStates[ n ] := TState():New( n ) } )
aStates[ 1 ]:AddOption( aStates[ 5 ] )
aStates[ 2 ]:AddOption( aStates[ 4 ] )
aStates[ 2 ]:AddOption( aStates[ 6 ] )
aStates[ 3 ]:AddOption( aStates[ 4 ] )
aStates[ 4 ]:AddOption( aStates[ 2 ] )
aStates[ 4 ]:AddOption( aStates[ 3 ] )
aStates[ 4 ]:AddOption( aStates[ 5 ] )
aStates[ 5 ]:AddOption( aStates[ 1 ] )
aStates[ 5 ]:AddOption( aStates[ 4 ] )
aStates[ 5 ]:AddOption( aStates[ 6 ] )
aStates[ 6 ]:AddOption( aStates[ 2 ] )
aStates[ 6 ]:AddOption( aStates[ 5 ] )
return aStates
//----------------------------------------------------------------------------//
CLASS TState
DATA nId
DATA aOptions INIT {}
DATA nScore INIT 0
METHOD New( nId ) INLINE ::nId := nId, Self
METHOD AddOption( oState ) INLINE AAdd( ::aOptions, oState )
METHOD NextState()
ENDCLASS
//----------------------------------------------------------------------------//
METHOD NextState() CLASS TState
local n, nMax := 0, oState, aOptions
if Len( ::aOptions ) == 1
oState = ::aOptions[ 1 ]
else
aOptions = AShuffle( AClone( ::aOptions ) )
for n = 1 to Len( aOptions )
if aOptions[ n ]:nScore >= nMax
nMax = aOptions[ n ]:nScore
oState = aOptions[ n ]
endif
next
endif
if oState:nId == 6
::nScore += .1
else
::nScore -= .1
endif
return oState
//----------------------------------------------------------------------------//
function AShuffle( aArray )
return ASort( aArray,,, { || HB_RandomInt( 1, 1000 ) < HB_RandomInt( 1, 1000 ) } )
//----------------------------------------------------------------------------//
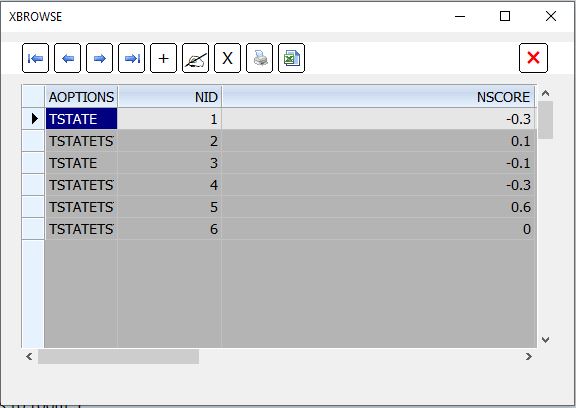
Después de uns pocos intentos, el robot comienza a aprender. Podemos comprobarlo revisando los distintos valores nScore de los estados:
Cuando el robot está en la habitación 5, él tiene tres alternativas: habitación 1 (nScore es -0.3), habitación 4 (nScore es -0.3) y opción 6 (nScore cero).
por lo que elige el valor más alto y sabe que la opción 6 es la correcta