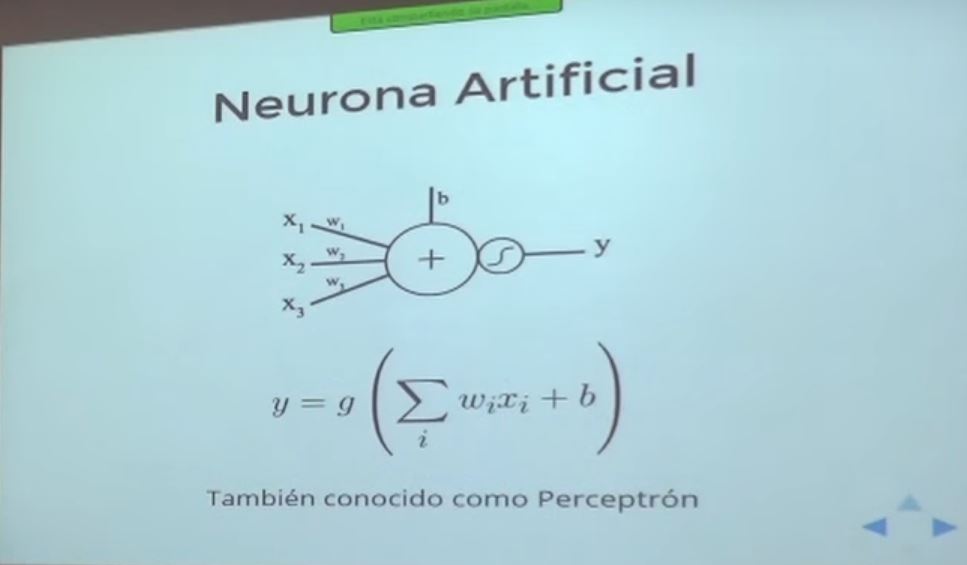
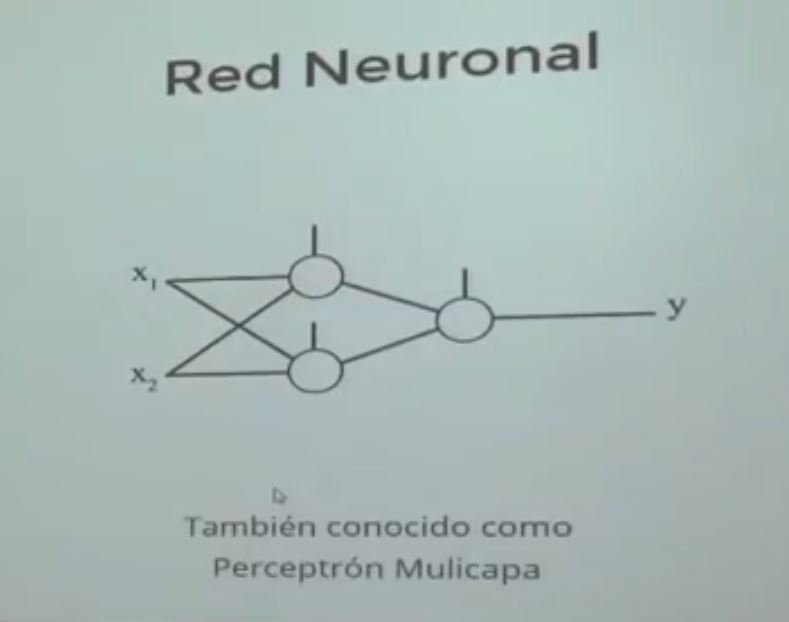
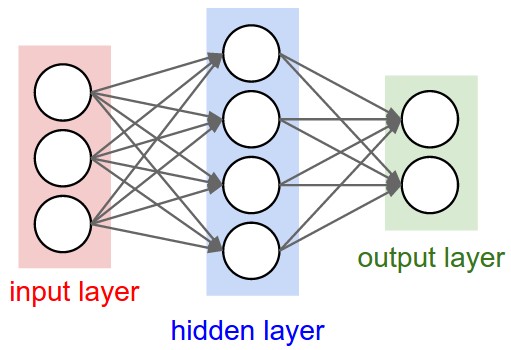
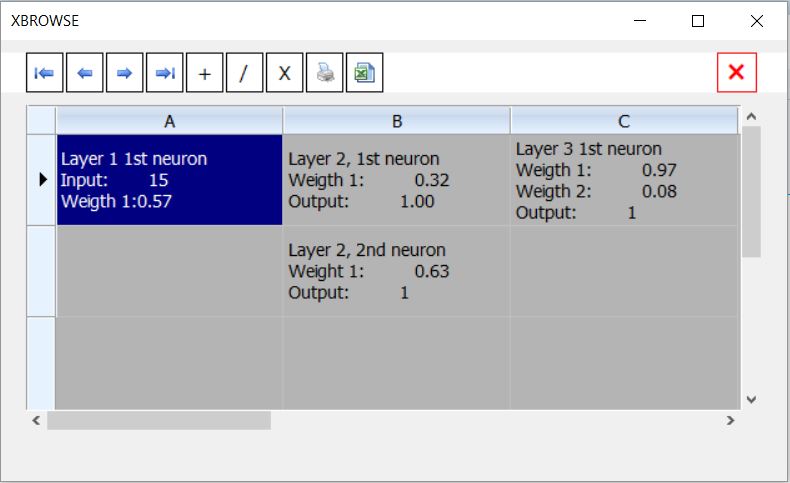
Code: Select all | Expand
#define CMDIFFSTEPSIZE 1 #define DYNAMIC_LEARNING 0 #include <errno.h>#include <fcntl.h>#include <math.h>#include <stdio.h>#include <stdlib.h>#include <string.h>#include <unistd.h>#include <sys/stat.h>#include <sys/types.h>#include "backprop.h"static void bkp_setup_all(bkp_network_t *n);static void bkp_forward(bkp_network_t *n);static void bkp_backward(bkp_network_t *n);#define sigmoid(x) (1.0 / (1.0 + (float)exp(-(double)(x))))#define sigmoidDerivative(x) ((float)(x)*(1.0-(x))) #define random() ((((float)rand()/(RAND_MAX)) * 2.0) - 1.0)int bkp_create_network(bkp_network_t **n, bkp_config_t *config){ if (config->Type != BACKPROP_TYPE_NORMAL) { errno = EINVAL; return -1; } if ((*n = (bkp_network_t *) malloc(sizeof(bkp_network_t))) == NULL) { errno = ENOMEM; return -1; } (*n)->NumInputs = config->NumInputs; (*n)->NumHidden = config->NumHidden; (*n)->NumOutputs = config->NumOutputs; (*n)->NumConsecConverged = 0; (*n)->Epoch = (*n)->LastRMSError = (*n)->RMSSquareOfOutputBetas = 0.0; (*n)->NumBias = 1; if (config->StepSize == 0) (*n)->StepSize = 0.5; else (*n)->StepSize = config->StepSize;#if CMDIFFSTEPSIZE (*n)->HStepSize = 0.1 * (*n)->StepSize;#endif if (config->Momentum == -1) (*n)->Momentum = 0.5; else (*n)->Momentum = config->Momentum; (*n)->Cost = config->Cost; if (((*n)->GivenInputVals = (float *) malloc((*n)->NumInputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->GivenDesiredOutputVals = (float *) malloc((*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->IHWeights = (float *) malloc((*n)->NumInputs * (*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->PrevDeltaIH = (float *) malloc((*n)->NumInputs * (*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->PrevDeltaHO = (float *) malloc((*n)->NumHidden * (*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->PrevDeltaBH = (float *) malloc((*n)->NumBias * (*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->PrevDeltaBO = (float *) malloc((*n)->NumBias * (*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->HiddenVals = (float *) malloc((*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->HiddenBetas = (float *) malloc((*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->HOWeights = (float *) malloc((*n)->NumHidden * (*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->BiasVals = (float *) malloc((*n)->NumBias * sizeof(float))) == NULL) goto memerrorout; if (((*n)->BHWeights = (float *) malloc((*n)->NumBias * (*n)->NumHidden * sizeof(float))) == NULL) goto memerrorout; if (((*n)->BOWeights = (float *) malloc((*n)->NumBias * (*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->OutputVals = (float *) malloc((*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; if (((*n)->OutputBetas = (float *) malloc((*n)->NumOutputs * sizeof(float))) == NULL) goto memerrorout; bkp_setup_all(*n); return 0; memerrorout: bkp_destroy_network(*n); errno = ENOMEM; return -1;}void bkp_destroy_network(bkp_network_t *n){ if (n == NULL) return; if (n->GivenInputVals == NULL) return; bkp_clear_training_set(n); free(n->GivenInputVals); if (n->GivenDesiredOutputVals != NULL) { free(n->GivenDesiredOutputVals); n->GivenDesiredOutputVals = NULL; } if (n->IHWeights != NULL) { free(n->IHWeights); n->IHWeights = NULL; } if (n->PrevDeltaIH != NULL) { free(n->PrevDeltaIH); n->PrevDeltaIH = NULL; } if (n->PrevDeltaHO != NULL) { free(n->PrevDeltaHO); n->PrevDeltaHO = NULL; } if (n->PrevDeltaBH != NULL) { free(n->PrevDeltaBH); n->PrevDeltaBH = NULL; } if (n->PrevDeltaBO != NULL) { free(n->PrevDeltaBO); n->PrevDeltaBO = NULL; } if (n->HiddenVals != NULL) { free(n->HiddenVals); n->HiddenVals = NULL; } if (n->HiddenBetas != NULL) { free(n->HiddenBetas); n->HiddenBetas = NULL; } if (n->HOWeights != NULL) { free(n->HOWeights); n->HOWeights = NULL; } if (n->BiasVals != NULL) { free(n->BiasVals); n->BiasVals = NULL; } if (n->BHWeights != NULL) { free(n->BHWeights); n->BHWeights = NULL; } if (n->BOWeights != NULL) { free(n->BOWeights); n->BOWeights = NULL; } if (n->OutputVals != NULL) { free(n->OutputVals); n->OutputVals = NULL; } if (n->OutputBetas != NULL) { free(n->OutputBetas); n->OutputBetas = NULL; } n->GivenInputVals = NULL; free(n);}int bkp_set_training_set(bkp_network_t *n, int ntrainset, float *tinputvals, float *targetvals){ if (!n) { errno = ENOENT; return -1; } bkp_clear_training_set(n); n->NumInTrainSet = ntrainset; n->TrainSetInputVals = tinputvals; n->TrainSetDesiredOutputVals = targetvals; return 0;}void bkp_clear_training_set(bkp_network_t *n){ if (n->NumInTrainSet > 0) { n->TrainSetInputVals = NULL; n->TrainSetDesiredOutputVals = NULL; n->NumInTrainSet = 0; }}static void bkp_setup_all(bkp_network_t *n){ int i, h, o, b; n->InputReady = n->DesiredOutputReady = n->Learned = 0; n->LearningError = 0.0; for (i = 0; i < n->NumInputs; i++) n->GivenInputVals[i] = 0.0; for(h = 0; h < n->NumHidden; h++) { n->HiddenVals[h] = 0.0; for (i = 0; i < n->NumInputs; i++) { n->IHWeights[i+(h*n->NumInputs)] = random(); n->PrevDeltaIH[i+(h*n->NumInputs)] = 0.0; } for (b = 0; b < n->NumBias; b++) { n->BHWeights[b+(h*n->NumBias)] = random(); n->PrevDeltaBH[b+(h*n->NumBias)] = 0.0; } } for(o = 0; o < n->NumOutputs; o++) { n->OutputVals[o] = 0.0; for (h = 0; h < n->NumHidden; h++) { n->HOWeights[h+(o*n->NumHidden)] = random(); n->PrevDeltaHO[h+(o*n->NumHidden)] = 0.0; } for (b = 0; b < n->NumBias; b++) { n->BOWeights[b+(o*n->NumBias)] = random(); n->PrevDeltaBO[b+(o*n->NumBias)] = 0.0; } } for (b = 0; b < n->NumBias; b++) n->BiasVals[b] = 1.0;}int bkp_learn(bkp_network_t *n, int ntimes){ int item, run; if (!n) { errno = ENOENT; return -1; } if (n->NumInTrainSet == 0) { errno = ESRCH; return -1; } for (run = 0; run < ntimes; run++) { for (item = 0; item < n->NumInTrainSet; item++) { n->InputVals = &(n->TrainSetInputVals[item*n->NumInputs]); n->DesiredOutputVals = &(n->TrainSetDesiredOutputVals[item*n->NumOutputs]); bkp_forward(n); bkp_backward(n); } n->Epoch++; n->LastRMSError = sqrt(n->RMSSquareOfOutputBetas / (n->NumInTrainSet * n->NumOutputs)); n->RMSSquareOfOutputBetas = 0.0; #if DYNAMIC_LEARNING if (n->Epoch > 1) { if (n->PrevRMSError < n->LastRMSError) { n->NumConsecConverged = 0; n->StepSize *= 0.95; #if CMDIFFSTEPSIZE n->HStepSize = 0.1 * n->StepSize;#endif#ifdef DISPLAYMSGS printf("Epoch: %d Diverging: Prev %f, New %f, Step size %f\n", n->Epoch, n->PrevRMSError, n->LastRMSError, n->StepSize);#endif } else if (n->PrevRMSError > n->LastRMSError) { n->NumConsecConverged++; if (n->NumConsecConverged == 5) { n->StepSize += 0.04; #if CMDIFFSTEPSIZE n->HStepSize = 0.1 * n->StepSize;#endif#ifdef DISPLAYMSGS printf("Epoch: %d Converging: Prev %f, New %f, Step size %f\n", n->Epoch, n->PrevRMSError, n->LastRMSError, n->StepSize);#endif n->NumConsecConverged = 0; } } else { n->NumConsecConverged = 0; } } n->PrevRMSError = n->LastRMSError;#endif } n->Learned = 1; return 0;}int bkp_evaluate(bkp_network_t *n, float *eoutputvals, int sizeofoutputvals){ if (!n) { errno = ENOENT; return -1; } if (!n->InputReady) { errno = ESRCH; return -1; } if (!n->Learned) { errno = ENODEV; return -1; } n->InputVals = n->GivenInputVals; n->DesiredOutputVals = n->GivenDesiredOutputVals; bkp_forward(n); if (eoutputvals) { if (sizeofoutputvals != n->NumOutputs*sizeof(float)) { errno = EINVAL; return -1; } memcpy(eoutputvals, n->OutputVals, n->NumOutputs*sizeof(float)); } return 0;}static void bkp_forward(bkp_network_t *n){ int i, h, o, b; n->LearningError = 0.0; for (h = 0; h < n->NumHidden; h++) { n->HiddenVals[h] = 0.0; n->HiddenBetas[h] = 0.0; for (i = 0; i < n->NumInputs; i++) n->HiddenVals[h] = n->HiddenVals[h] + (n->InputVals[i] * n->IHWeights[i+(h*n->NumInputs)]); for (b = 0; b < n->NumBias; b++) n->HiddenVals[h] = n->HiddenVals[h] + (n->BiasVals[b] * n->BHWeights[b+(h*n->NumBias)]); n->HiddenVals[h] = sigmoid(n->HiddenVals[h]); } for (o = 0; o < n->NumOutputs; o++) { n->OutputVals[o] = 0.0; for (h = 0; h < n->NumHidden; h++) n->OutputVals[o] = n->OutputVals[o] + (n->HiddenVals[h] * n->HOWeights[h+(o*n->NumHidden)]); for (b = 0; b < n->NumBias; b++) n->OutputVals[o] = n->OutputVals[o] + (n->BiasVals[b] * n->BOWeights[b+(o*n->NumBias)]); n->OutputVals[o] = sigmoid(n->OutputVals[o]); n->LearningError = n->LearningError + ((n->OutputVals[o] - n->DesiredOutputVals[o]) * (n->OutputVals[o] - n->DesiredOutputVals[o])); } n->LearningError = n->LearningError / 2.0;}static void bkp_backward(bkp_network_t *n){ float deltaweight; int i, h, o, b; for (o = 0; o < n->NumOutputs; o++) { n->OutputBetas[o] = n->DesiredOutputVals[o] - n->OutputVals[o]; n->RMSSquareOfOutputBetas += (n->OutputBetas[o] * n->OutputBetas[o]); for (h = 0; h < n->NumHidden; h++) { n->HiddenBetas[h] = n->HiddenBetas[h] + (n->HOWeights[h+(o*n->NumHidden)] * sigmoidDerivative(n->OutputVals[o]) * n->OutputBetas[o]);#if CMDIFFSTEPSIZE deltaweight = n->HiddenVals[h] * n->OutputBetas[o];#else deltaweight = n->HiddenVals[h] * n->OutputBetas[o] * sigmoidDerivative(n->OutputVals[o]);#endif n->HOWeights[h+(o*n->NumHidden)] = n->HOWeights[h+(o*n->NumHidden)] + (n->StepSize * deltaweight) + (n->Momentum * n->PrevDeltaHO[h+(o*n->NumHidden)]); n->PrevDeltaHO[h+(o*n->NumHidden)] = deltaweight; } for (b = 0; b < n->NumBias; b++) {#if CMDIFFSTEPSIZE deltaweight = n->BiasVals[b] * n->OutputBetas[o];#else deltaweight = n->BiasVals[b] * n->OutputBetas[o] + sigmoidDerivative(n->OutputVals[o]);#endif n->BOWeights[b+(o*n->NumBias)] = n->BOWeights[b+(o*n->NumBias)] + (n->StepSize * deltaweight) + (n->Momentum * n->PrevDeltaBO[b+(o*n->NumBias)]); n->PrevDeltaBO[b+(o*n->NumBias)] = deltaweight; } } for (h = 0; h < n->NumHidden; h++) { for (i = 0; i < n->NumInputs; i++) { deltaweight = n->InputVals[i] * sigmoidDerivative(n->HiddenVals[h]) * n->HiddenBetas[h]; n->IHWeights[i+(h*n->NumInputs)] = n->IHWeights[i+(h*n->NumInputs)] + #if CMDIFFSTEPSIZE (n->HStepSize * deltaweight) +#else (n->StepSize * deltaweight) +#endif (n->Momentum * n->PrevDeltaIH[i+(h*n->NumInputs)]); n->PrevDeltaIH[i+(h*n->NumInputs)] = deltaweight; if (n->Cost) n->IHWeights[i+(h*n->NumInputs)] = n->IHWeights[i+(h*n->NumInputs)] - (n->Cost * n->IHWeights[i+(h*n->NumInputs)]); } for (b = 0; b < n->NumBias; b++) { deltaweight = n->BiasVals[b] * n->HiddenBetas[h] * sigmoidDerivative(n->HiddenVals[h]); n->BHWeights[b+(h*n->NumBias)] = n->BHWeights[b+(h*n->NumBias)] +#if CMDIFFSTEPSIZE (n->HStepSize * deltaweight) +#else (n->StepSize * deltaweight) +#endif (n->Momentum * n->PrevDeltaBH[b+(h*n->NumBias)]); n->PrevDeltaBH[b+(h*n->NumBias)] = deltaweight; if (n->Cost) n->BHWeights[b+(h*n->NumBias)] = n->BHWeights[b+(h*n->NumBias)] - (n->Cost * n->BHWeights[b+(h*n->NumBias)]); } }}int bkp_query(bkp_network_t *n, float *qlastlearningerror, float *qlastrmserror, float *qinputvals, float *qihweights, float *qhiddenvals, float *qhoweights, float *qoutputvals, float *qbhweights, float *qbiasvals, float *qboweights){ if (!n) { errno = ENOENT; return -1; } if (!n->Learned) { errno = ENODEV; return -1; } if (qlastlearningerror) *qlastlearningerror = n->LearningError; if (qlastrmserror) *qlastrmserror = n->LastRMSError; if (qinputvals) memcpy(qinputvals, n->InputVals, n->NumInputs*sizeof(float)); if (qihweights) memcpy(qihweights, n->IHWeights, (n->NumInputs*n->NumHidden)*sizeof(float)); if (qhiddenvals) memcpy(qhiddenvals, n->HiddenVals, n->NumHidden*sizeof(float)); if (qhoweights) memcpy(qhoweights, n->HOWeights, (n->NumHidden*n->NumOutputs)*sizeof(float)); if (qoutputvals) memcpy(qoutputvals, n->OutputVals, n->NumOutputs*sizeof(float)); if (qbhweights) memcpy(qbhweights, n->BHWeights, n->NumBias*n->NumHidden*sizeof(float)); if (qbiasvals) memcpy(qbiasvals, n->BiasVals, n->NumBias*sizeof(float)); if (qboweights) memcpy(qboweights, n->BOWeights, n->NumBias*n->NumOutputs*sizeof(float)); return 0;}int bkp_set_input(bkp_network_t *n, int setall, float val, float *sinputvals){ int i; if (!n) { errno = ENOENT; return -1; } if (setall) { for (i = 0; i < n->NumInputs; i++) n->GivenInputVals[i] = val; } else { memcpy(n->GivenInputVals, sinputvals, n->NumInputs*sizeof(float)); } n->InputReady = 1; return 0;}int bkp_set_output(bkp_network_t *n, int setall, float val, float *soutputvals){ int i; if (!n) { errno = ENOENT; return -1; } if (setall) { for (i = 0; i < n->NumOutputs; i++) n->GivenDesiredOutputVals[i] = val; } else { memcpy(n->GivenDesiredOutputVals, soutputvals, n->NumOutputs*sizeof(float)); } n->DesiredOutputReady = 1; return 0;}int bkp_loadfromfile(bkp_network_t **n, char *fname){ char file_format; int fd, returncode; bkp_config_t config; returncode = -1; if ((fd = open(fname, O_RDONLY)) == -1) return returncode; if (read(fd, &file_format, sizeof(char)) == -1) goto cleanupandret; if (file_format != 'A') { errno = EINVAL; goto cleanupandret; } if (read(fd, &config.Type, sizeof(short)) == -1) goto cleanupandret; if (read(fd, &config.NumInputs, sizeof(int)) == -1) goto cleanupandret; if (read(fd, &config.NumHidden, sizeof(int)) == -1) goto cleanupandret; if (read(fd, &config.NumOutputs, sizeof(int)) == -1) goto cleanupandret; if (read(fd, &config.StepSize, sizeof(float)) == -1) goto cleanupandret; if (read(fd, &config.Momentum, sizeof(float)) == -1) goto cleanupandret; if (read(fd, &config.Cost, sizeof(float)) == -1) goto cleanupandret; if (bkp_create_network(n, &config) == -1) { goto cleanupandret; } (*n)->InputVals = (*n)->GivenInputVals; (*n)->DesiredOutputVals = (*n)->GivenDesiredOutputVals; if (read(fd, (int *) &(*n)->NumBias, sizeof(int)) == -1) goto errandret; if (read(fd, (int *) &(*n)->InputReady, sizeof(int)) == -1) goto errandret; if (read(fd, (int *) &(*n)->DesiredOutputReady, sizeof(int)) == -1) goto errandret; if (read(fd, (int *) &(*n)->Learned, sizeof(int)) == -1) goto errandret; if (read(fd, (*n)->InputVals, (*n)->NumInputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->DesiredOutputVals, (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->IHWeights, (*n)->NumInputs * (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->PrevDeltaIH, (*n)->NumInputs * (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->PrevDeltaHO, (*n)->NumHidden * (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->PrevDeltaBH, (*n)->NumBias * (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->PrevDeltaBO, (*n)->NumBias * (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->HiddenVals, (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->HiddenBetas, (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->HOWeights, (*n)->NumHidden * (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->BiasVals, (*n)->NumBias * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->BHWeights, (*n)->NumBias * (*n)->NumHidden * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->BOWeights, (*n)->NumBias * (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->OutputVals, (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; if (read(fd, (*n)->OutputBetas, (*n)->NumOutputs * sizeof(float)) == -1) goto errandret; returncode = 0; goto cleanupandret;errandret: bkp_destroy_network(*n);cleanupandret: close(fd); return returncode;} int bkp_savetofile(bkp_network_t *n, char *fname){ int fd, returncode; short type = BACKPROP_TYPE_NORMAL; returncode = -1; fd = open(fname, O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);